Gunnar Atli Sigurdsson
Senior Applied Scientist at Amazon AGI
{firstletterofmyfirstname}@{myfirstname}.xyz
My research focuses on multimodal learning across video, text, 3D, audio, and robotics.
Senior Applied Scientist at Amazon AGI
{firstletterofmyfirstname}@{myfirstname}.xyz
My research focuses on multimodal learning across video, text, 3D, audio, and robotics.
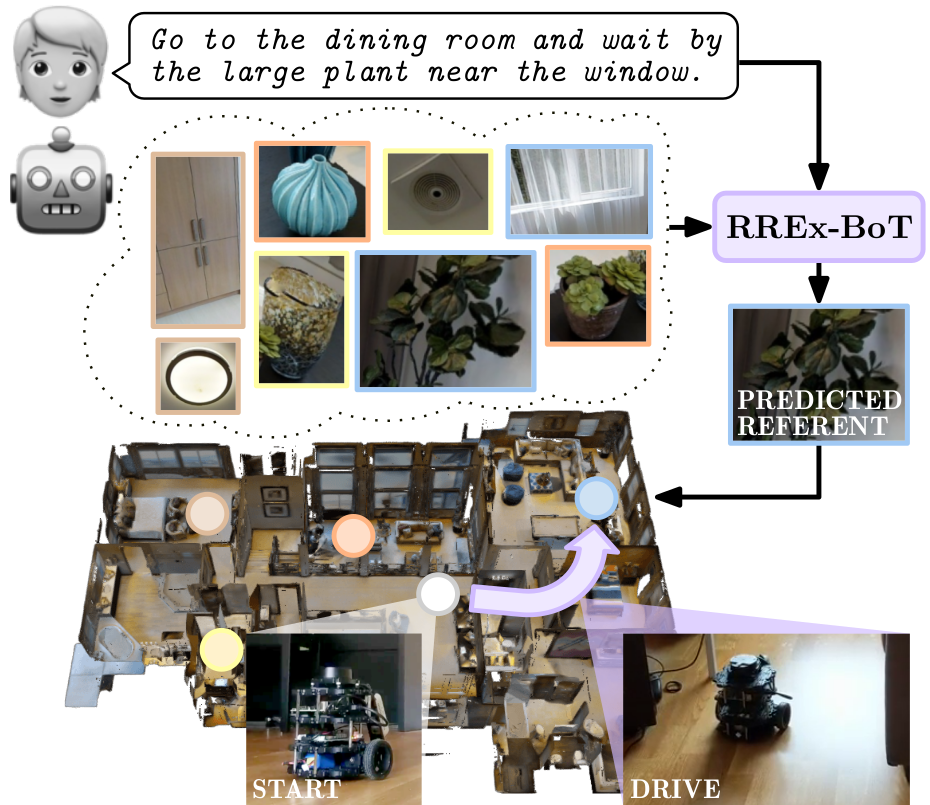
Household robots operate in the same space for years. Such robots incrementally build dynamic maps that can be used for tasks requiring remote object localization. In an observed environment, locating an object requires searching among all objects in the environment and comes with various challenges, including privacy. We apply vision-language models to these large 3d search spaces.
There are thousands of actively spoken languages on Earth, but a single visual world. Grounding in this visual world has the potential to bridge the gap between all these languages. Our goal is to use visual grounding to improve unsupervised word mapping between languages. The key idea is to establish a common visual representation between two languages by learning embeddings from unpaired instructional videos narrated in the native language. Given this shared embedding we demonstrate that (i) we can map words between the languages, particularly the 'visual' words; (ii) that the shared embedding provides a good initialization for existing unsupervised text-based word translation techniques, forming the basis for our proposed hybrid visual-text mapping algorithm, MUVE; and (iii) our approach achieves superior performance by addressing the shortcomings of text-based methods -- it is more robust, handles datasets with less commonality, and is applicable to low-resource languages. We apply these methods to translate words from English to French, Korean, and Japanese -- all without any parallel corpora and simply by watching many videos of people speaking while doing things.


Several theories in cognitive neuroscience suggest that when people interact with the world, or simulate interactions, they do so from a first-person egocentric perspective, and seamlessly transfer knowledge between third-person (observer) and first-person (actor). Despite this, learning such models for human action recognition has not been achievable due to the lack of data. This paper takes a step in this direction, with the introduction of Charades-Ego, a large-scale dataset of paired first-person and third-person videos, involving 112 people, with 4000 paired videos. This enables learning the link between the two, actor and observer perspectives. Thereby, we address one of the biggest bottlenecks facing egocentric vision research, providing a link from first-person to the abundant third-person data on the web. We use this data to learn a joint representation of first and third-person videos, with only weak supervision, and show its effectiveness for transferring knowledge from the third-person to the first-person domain.
Computer vision has a great potential to help our daily lives by searching for lost keys, watering flowers or reminding us to take a pill. To succeed with such tasks, computer vision methods need to be trained from real and diverse examples of our daily dynamic scenes. While most of such scenes are not particularly exciting, they typically do not appear on YouTube, in movies or TV broadcasts. So how do we collect sufficiently many diverse but boring samples representing our lives? We propose a novel Hollywood in Homes approach to collect such data. Instead of shooting videos in the lab, we ensure diversity by distributing and crowdsourcing the whole process of video creation from script writing to video recording and annotation. Following this procedure we collect a new dataset, Charades, with hundreds of people recording videos in their own homes, acting out casual everyday activities.


What does a typical visit to Paris look like? In this work, we show how to automatically learn the temporal aspects, or storylines of visual concepts from web data. Our novel Skipping Recurrent Neural Network (S-RNN) uses a framework that skips through the images in the photo stream to explore the space of all ordered subsets of the albums.
Image segmentation algorithms commonly return segmentation masks that represent the shape of objects. Particularly, in the medical imaging domain, this shape incorporates information about, for example, the state of the segmented organ. By looking at the shape of an object, in two or three dimensions, it is possible to look for signs of disease.



Using modern diffusion weighted magnetic resonance imaging protocols, the orientations of multiple neuronal fiber tracts within each voxel can be estimated. Further analysis of these populations, including application of fiber tracking and tract segmentation methods, is often hindered by lack of spatial smoothness of the estimated orientations. For example, a single noisy voxel can cause a fiber tracking method to switch tracts in a simple crossing tract geometry. In this work, a generalized spatial smoothing framework that handles multiple orientations as well as their fractional contributions within each voxel is proposed.
The Icelandic biomedical company, Nox Medical, provides solutions for sleep monitoring and diagnostics. With portable sleep monitors, there is opportunity to measure large population of people in their own beds. From this data, we are interested in exploring relationships between underlying disease and measurements. We performed statistical analysis on various time-series from the device and looked at the discriminative power of various features for classifying events. Using regression and classification algorithms, such as neural networks, we were able to predict vibration in patients from sounds, and warrant further study of relationships with disease. Our work was incorporated in to the company's software suite, Noxturnal.


The immense popularity of wireless communications has left the common frequency bands crowded, prompting researchers to utilize available spectrum at ever higher frequencies. At mm-wave frequencies there is pronounced need for novel antenna designs that are tightly integrated with their driving circuitry in order to reduce power losses. A radiator concept for 94 GHz CMOS-technology was reviewed, scaled up, and redesigned to work at 2.4 GHz on a FR-4 printed circuit board, in the interest of testing the concept. The radiator works in similar manner to an array of dipoles, and can connect directly to the last amplifier stage without impedance matching, due to load-pull matched input impedances, accomplishing all of its power combining in the air. 3D full-wave electromagnetic field simulations were performed on all transmission line structures and furthermore, various ways to achieve symmetric power splitting and shorted transmission line stubs with coupled lines were designed and experimented with, in order to achieve acceptable efficiency and radiation pattern of the radiating array. Work with Steven Bowers and Ali Hajimiri at Caltech.
CV available on request.
Please see my GitHub page for released code.